![]()
UML Tools, IDEs, Application Servers, Data Sources and PE:J®
The Productivity Environment™ for Java™ (PE:J®) is hywy Software’s flagship product created to facilitate iterative, team-based software creation, deployment, and maintenance. Using PE:J® makes the user understand the potential of integrating existing software development methodologies, UML modeling, development, deployment, and maintenance of software all within a single environment. PE:J® has been designed with features that facilitate enterprise team development to create and maintain software on time, under budget, with all the desired features.
Introduction
To start with, I have to make something very clear. PE:J® is neither a UML Modeling tool, nor a Java IDE/Debugger, nor a J2EE Application Server, nor an RDBMS. PE:J® can be used independent of any UML Modeling tools, or Java IDEs/Debuggers, or J2EE Application Servers, or RDBMSs. It is neither of these; although it has a whole slew of features on its own that are unique by themselves and not present in any of these tools. However, with PE:J®’s unique features, combined with features that other tools offer, it works with all these tools to create great software.
PE:J® is Application Infrastructure Software that rapidly cuts down the software creation to completion lifecycle time and increases productivity multi-fold.
Using PE:J®,
-
Makes Round-Trip software engineering a reality
-
Allows the ability to start projects at any time in the development lifecycle
-
Creates a complete open environment, offering endless customization
-
Provides a way to structure the user’s project and product standards
-
Allows the user to work the way they want without mandating procedures
-
Facilitates team development across the enterprise
-
Allows team development with artifacts that are standardized, user-customizable, and granular
-
Facilitates the iterative development process
-
Allows continuous and rapid product prototyping, development, maintenance, and improvement
PE:J® provides teams the ability to collaborate and work to build real world applications involving multiple components, thousands of LOC, and multiple developers in a natural and effective manner. There are a myriad ways of using PE:J® to achieve the same result and the user can decide which technique is appropriate at that time. User-customizable templates allow the user to control every aspect of code generation to meet their corporate standards and the unique demands of each project and every product. Users can enforce their own coding and design standards for new projects, or they can bring existing work in tune with their current standards.
PE:J® has been designed with a strategic and long-term focus for building multi-tier Enterprise Applications within any corporation. Therefore PE:J® has been designed such that it would:
-
Support the latest industry standards and be extensible to incorporate new and existing standards as and when they emerge
-
Provide complete support for the entire application life-cycle
-
Focus on maximizing user productivity in the light of increasing application and architectural complexity.
One of the greatest strengths of PE:J® is its ability to co-exist with existing UML Tools, Java Integrated Development Environments (IDE)/Debuggers, J2EE Application Servers, and RDBMSs. Moreover, PE:J® facilitates their use seamlessly during product development and maintenance. PE:J®, in addition to providing a host of unique productivity features, also provides sweet-spot functionality not provided by other tools - UML tools, or IDEs, or J2EE Application Servers or RDBMSs. However, PE:J® integrates and combines its features with existing tools to provide the user with a unique integrated productivity environment to work in. PE:J® integrates with a whole list of UML Tools, IDEs, J2EE Application Servers and RDBMSs to provide the user with a unique seamless productivity environment experience. The tools may be anything from this list below:
UML Tools
-
TogetherSoft’s ControlCenter
-
Rational’s Rose and XDE products
-
Gentleware’s Posideon
-
Argo UML
-
Any XMI compliant UML Tool
Java IDEs/Debuggers
-
Eclipse
-
WebSphere Application Developer (WSAD)
-
Forte for Java
-
NetBeans
-
JBuilder, TogetherJ, JDeveloper, IntelliJ and a whole host of other Java IDEs
J2EE Application/Web Servers
-
BEA WebLogic Application Server
-
IBM WebSphere Application Server
Relational Database Management Systems (RDBMS)
-
Oracle
-
IBM’s DB2/Universal Database (UDB)
-
Microsoft’s SQL Server
We at hywy software are convinced that the tight integration that we provide in PE:J® between existing UML modeling tools, IDEs, J2EE Application Servers, and RDBMSs will be a key success factor for managing complexity and delivering enterprise applications based on the latest industry standards.
The unique requirements of an ideal Productivity Environment
In today’s world, where enterprise architectures are a mix of the old and the new, much effort is dedicated to making every solution work seamlessly. Applications are required to integrate with one another, be securely exposed over the Web, be flexible and responsive to changing strategies, while at the same time satisfying the continual demand for improved ‘abilities’ – availability, reliability, scalability, interoperability, and manageability. In addition, the applications themselves are expected to do more in terms of functionality, incorporating workflow, business process and logic, and supporting a range of channels.
PE:J® provides a flexible and customizable environment that simplifies Application Development and provides extensive support for all the stages involved in the application software development lifecycle, right from modeling through development, deployment, testing, and maintenance. In addition it allows teams to share models, code, and components, across an entire team of business analysts, architects, developers, managers, and testers uniting the various roles involved in software creation, development, and maintenance of applications.
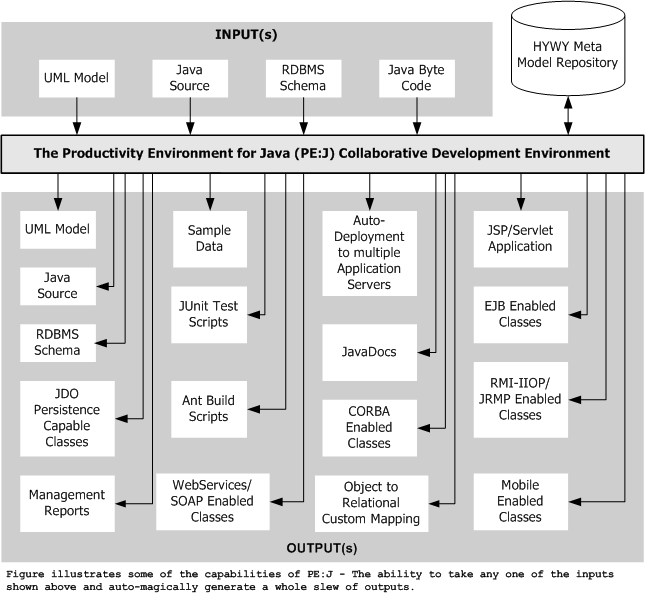
UML modeling support
For modeling, PE:J® allows you to work with your favorite tool of choice – be it TogetherSoft’s ControlCenter, or Rational’s Rose or XDE, or Gentleware’s Posideon, or Argo’s UML, or any other XMI compliant modeling tool that you normally use. PE:J® will then read the artifacts created from your UML tool of choice and integrate it into the hywy PE:J® meta model repository. While PE:J® integrates seamlessly with Rational, or TogetherSoft, or any other XMI compliant UML editor tool, it does not provide a UML editor on it’s own.
User-customizable templates
PE:J® allows corporate, project, and product-specific standards to be imposed on code generation – be it Java source code generation, or JSP/Servlet generation, or Persistence Layer generation, or JUnit Test-code generation, or EJB Session Bean code generation, or ANT Build Script generation, or HTML page generation, etc. PE:J® uses the Open Source Velocity Project from the Apache Software Foundation for any type of generation. As long as users learn how to customize the templates which are developed as Velocity macros, they can make PE:J® generate any artifact that conforms to the user-customizable templates.
Unfortunately, other tools like Together’s ControlCenter, only allow you to customize their Java source code generation facilities.
Java Source-code Generation
PE:J® provides complete customization of Java source code that it generates from the top of the source-code file to the very last line, and everything in between. All the user will have to do, is to modify the Velocity macro corresponding to the Java source code generation template, and everything generated will conform to the user’s corporate project, or product standard as has been specified in the Velocity macros modified by the user.
Meta Model Merges
PE:J® provides the user the ability to merge between one model and the other. The information for the model in question may be from UML, or Java Source code, or Java Byte code, or an RDBMS schema. It is also possible for users to read information from other artifacts once they can create a parser and provide hooks to PE:J®’s Meta Model Merger using PE:J®’s meta model API. Similarly, users can use PE:J®’s meta model API to create a either a merger or a generator to either merge or generate their own specific artifact if they need to. For example, it is possible for users to create a merger to read C#.NET code and populate the hywy PE:J® meta model with information. Similarly, nothing prevents a user from writing a C#.NET source code generator that can spit out C#.NET code from information present in the PE:J® meta model repository.
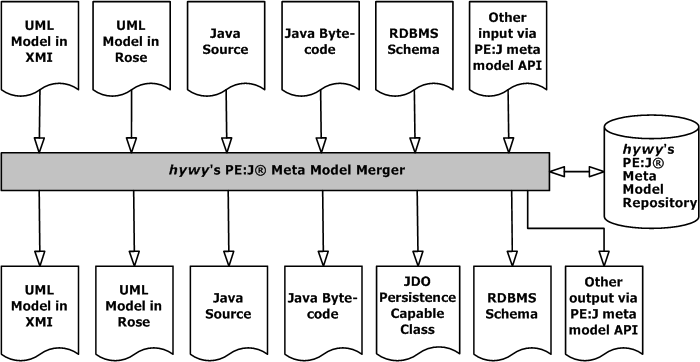
PE:J®’s meta-model mergers, merge the changes from one model to the other and update the repository based on user preferences whether they want the information from the new model to be added, removed or merged in the destination model. PE:J® provides a model merge graphical interface where the users have the choice of specifying their preferences.
Except PE:J®, None of the other tools mentioned in this document provide this feature.
Management Reports
At the time of model merges, PE:J® also provides reports that will tell the user what changed between one version and the other. This is helpful as this provides useful information that is useful for project management. Based on these reports, project management can decide how or what changed between one model merge and the other which helps a lot in making informed decisions.
Except PE:J®, None of the other tools mentioned in this document provide this feature.
Auto-Generated Ant Build Scripts
Any time Java sources are created using PE:J®, an Ant Build script is automatically generated for the project making it helpful to create future builds of the project. If an Ant build script already exists for the project, the Java Sources are added to the existing build script. The Ant project is once again an Open Source project from the Apache Software Foundation, and is the industry standard for creating and executing automated scripts.
Except PE:J®, None of the other tools mentioned in this document provide this feature.
Reverse Engineering Java Sources
Reverse engineering Java sources is useful for a number of reasons. PE:J® can be used against pre-existing Java Sources to improve model understanding. It is useful to effortlessly monitor on-going development to ensure the model shape is being maintained as development is going on. It also reduces the cost of maintenance as it provides users the ability to see the big picture and not just lines of Java source code in a Java text editor/IDE. And the biggest advantage is that it provides the ability to pick-up existing project sources and automatically JDO persistence-enable them.
Support for this last feature viz., JDO persistence-enabling ability, is only provided by PE:J®, and is not provided by any of the other tools mentioned in this document.
Reverse Engineering RDB Schema
Reverse engineering RDBMS schema is useful for a number of reasons. If the users want to start from an RDBMS schema, it is possible to create a UML model from the schema, and then generate Java sources from the schema, and go on and create Persistence Capable classes from the schema. Once that’s done, it is possible to create JSP/Servlet or EJB façade applications that use the generated persistence layer.
This is a really powerful feature that except PE:J®, none of the other tools mentioned in this document provide.
Edit/Debug Code
Like I mentioned earlier, PE:J® is not a Java IDE or text editor or debugger. PE:J® allows you to work with your favorite editor of choice to edit your Java sources if you need to.
JDO Persistence
PE:J® provides the ability to persistence enable your application. The persistence layer that is auto-generated for the user is based on the latest JDO standard. The user submits Java Sources with the business logic added in them to hywy’s PE:J® JDO Class Enhancer, and PE:J® takes you from there to create persistence capable classes with persistence hooks auto-magically added to them that users no longer need to hand-code their persistence at all. From then on, persistence is handled for the user transparently.
Except PE:J®, None of the other tools mentioned in this document provide this feature.
Byte-code vs. Source-code JDO Enhancement
A lot of people have expressed severe objections to byte code JDO persistence enhancement. They don't like things being done to their code which they can't see in the source. However, the JDO specification itself does not prescribe how the persistence modifications are to be made; only the contract that is to be supported.
However, PE:J® is the only JDO implementation available that provides Source-Code JDO Enhancement and addresses these concerns effectively.
Entity Bean Persistence
PE:J® does not generate persistence based on the Entity Bean specification. It however, does not prevent the user from hand-coding Entity Bean (Bean Managed) persistence themselves.
There are a lot of problems associated with Entity Bean persistence and the users of this approach have to be careful when designing and developing Entity Beans. The problems related to using Entity Beans for persistence and how JDO solves them are detailed in my whitepaper titled EJB and JDO and are outside the scope of this document.
However, PE:J® can be used to provide the persistence layer for Entity Beans.
Proprietary Persistence
PE:J® does not provide proprietary persistence. However, PE:J® does not prevent the user from hand-coding any proprietary persistence management themselves if they needed it.
Distributed Object Cache
To really increase application performance, an object cache is an absolute necessity if we have to reduce the number of database round-trips, and the resulting network round-trips (if the database were remote). Since PE:J® provides persistence based on JDO which requires the presence of an object cache, users can be assured of high performing applications during run-time.
Except for J2EE Application Servers and Databases, and PE:J®, none of the other tools mentioned in this document provide this feature.
Generate a default Object to Relational mapping layer
PE:J® can create an Object to Relational mapping layer for the Java sources presented to it. As long as the user identifies the classes, their attributes, and the type of object identity that they need each class to have in the PE:J® Enhancer pane, PE:J® can automatically generate an Object/Relational mapping layer for you and apply the resulting relational schema to the database.
Except for J2EE Application Servers which provide Container Managed Entity Bean persistence (CMP), and PE:J® which provides persistence based on JDO, none of the other tools mentioned in this document provide this feature.
Custom mapping between object and legacy relational models (Custom O/R Mapping)
If the user has an existing Object Model with Java sources, and an existing database schema, PE:J® allows the user to customize the mapping between the Object Model and the Relational model using the PE:J® Object to Relational mapper pane. PE:J® provides multiple mapping strategies to customize mapping for both uni-directional and bi-directional relationships, be they one-to-one, one-to-many, or many-to-many.
Based on relationship cardinalities, relationship navigability, and the types of objects involved in a relationship there are totally seventy two possible relationship configurations. Of these, forty nine are illegal relationship configurations. Of the twenty three valid relationship configurations, there are multiple configuration scenarios possible. PE:J® provides innumerable different customizable mapping options to map these valid relationship configurations from the Object domain model to the relational model.
More detailed explanations on how to use PE:J® to customize Object to Relational mapping is provided in the PE:J® Object to Relational Mapping User Guide Manual for the Developer Edition version 2.2.0 and are outside the scope of this document.
Except PE:J®, None of the other tools mentioned in this document provide this feature.
Schema Evolution
Over time, there may be many changes to the structure of the domain objects to persist more pieces of information. In such cases, PE:J® provides the user to pick up an existing project where an Object to Relational Mapping has already been specified, and allow the user to make changes to the mapping, or add more tables or fields to the relational model or attributes in the case of an Object Model and rework the mapping.
Except PE:J®, None of the other tools mentioned in this document provide this feature.
Automated Session EJB Generation
Recognizing that the Session Bean Façade-JDO Persistence combination proves to be the best model for Enterprise Deployment, away from all the problems that Entity Beans introduce, PE:J® provides the ability to auto-generate J2EE Session EJB Applications that are developed using the Session EJB façade design pattern The user just needs to identify the Persistence-Aware Classes for which Session Facades are required, and the methods that he needs remoted in his object model, and PE:J® automatically generates Session EJB wrappers around these classes.
More detailed explanations on how to use PE:J® to automatically generate and auto-deploy Session Façade EJBs is provided in the PE:J® Auxiliary Operations User Guide Manual for the Developer Edition version 2.2.0 and are outside the scope of this document.
Automated JSP/Servlet Application Generation
Once a persistence layer is auto-generated by PE:J®, the user can request PE:J® to auto-generate a readily deployable JSP/Servlet application that makes use of the PE:J® generated persistence layer. This application is called The Object Editor.
The Object Editor is fully customizable and extensible by users based on changes they make to PE:J®’s user-customizable templates that are provided. The user can customize or extend this application either on a per-project, or on a per-product, or on a per-organization basis. Also, it is conceivable, for example, that an organization might have a uniform webpage look-and-feel across their enterprise, in which case, simple modifications made to PE:J®’s user-customizable templates will ensure that all JSP/Servlet pages generated by PE:J® will have the same and uniform look-and-feel. Or it is possible, for example, that a project/product requires the use of security TagLibs to be used on every page that’s generated. In such cases, once again, PE:J®’s user-customizable JSP/Servlet templates can be modified such that it is reflected in every page that PE:J® generates.
Except PE:J®, None of the other tools mentioned in this document provide this feature.
Webservices Generation
In the next release of PE:J®, it will be possible to use PE:J® to auto-generate Webservices for the persistence-aware classes in the user’s object model.
Mobile-enabling
In the next major release of PE:J®, it will be possible to use PE:J® to mobile-enable the persistence-aware classes in the user’s object model.
Auto-Deployment on J2EE Application/Web Servers
Once a JSP/Servlet-enabled or a Session EJB façade-enabled or a WebServices-enabled or Mobile-enabled application is auto-generated by PE:J®, it also packages it and auto-deploys the packaged application with all its required libraries at a location and on a J2EE Application/Web Server of the user’s choice. Before the application is packaged, a graphical interface is provided so the user can configure the deployment descriptors and deployment options for the application.
RDB Schema Generation
PE:J® can also generate an RDB schema based on how the user wants his schema to look like. The user has the ability to work with a graphical interface to create tables, and columns using PE:J®’s GUI and create an RDB schema. It is also possible to make PE:J® auto-generate an RDB schema that corresponds to an object model without generating any persistence layer that will create the hooks to persist the Domain Object model to the said relational model.
Sample Data Generation
No productivity environment is complete unless it can also auto-generate sample data so that the user can rapidly prototype and test whether the application that is generated and deployed not only works, but works according to the user’s requirements and satisfaction. PE:J® provides users the ability to generate sample data for the persistence layer that it generated.
Except PE:J®, None of the other tools mentioned in this document provide this feature.
Unit Test Application Generation
No productivity environment is complete unless it can also auto-generate unit test applications so the user need not hand-code these. PE:J® auto-generates unit test applications based on the JUnit framework. The JUnit framework originally developed by Eric Gamma of the ‘Design Patterns’ fame is the industry standard for unit testing. The user can direct PE:J® to auto-generate unit test applications for the persistence layer that it generated.
J2EE Services
PE:J® operates well in both a managed and non-managed environments. A J2EE Application/Web Server is not required to use PE:J and use the persistence layer that it generates. However, where there is a J2EE Application Server present, PE:J® delegates all J2EE services functionality to the J2EE Application Server, and itself acts as a slave to the J2EE Application Server.
Summary
What is really important when evaluating whether you need the functionality provided by a piece of software or not, is to prepare a set of requirements that are crucial to your company, products, and your projects. It is always good to define a list of required features, weigh the features, and make high-level passes at the list of potential candidates that you are evaluating and than make a decision.
However, like I said when I started off with this article, PE:J® is neither a UML Modeling tool, nor a Java IDE/Debugger, nor a J2EE Application Server, nor an RDBMS. PE:J® can be used independent of any UML Modeling tool, or Java IDE/Debugger, or J2EE Application Server, or RDBMS. It is neither of these; although it has a whole slew of features on its own that are unique by themselves and not present in any of these tools. However, with PE:J®’s unique features, combined with features that other tools offer, it works in tandem with all these tools to create great software.
About the Author
Gopalan Suresh Raj is the Chief Architect for HYWY Software Corporation (http://www.hywy.com/). He has been a Software Engineering Professional since 1991. His background includes Object-Oriented and Component-Oriented Design and Development in the areas of Medical-Systems, Process Automation, Target Marketing Systems, Manufacturing Systems, Object-Relational Persistence Mapping, Custom Control development, Cross-platform Applications development and Expert Systems. His expertise spans multi-tier Enterprise Component Architectures and Distributed Object Computing. His responsibilities have included the entire gamut of the Software Engineering project life cycle including Analysis, Design, Development and QA. He is also an active author, including contributions to Professional JMS Programming, Wrox Press, 2001; Enterprise Java Computing- Applications and Architecture, Cambridge University Press, 1999, and The Awesome Power of Java Beans, Manning Publications Co., 1998. He has submitted papers at international forums, and his work has been published in numerous technical journals. He has authored technical white papers for the OMG, and has also been on the white paper review panel for Sun Microsystems, Inc.Visit him at his Web Cornucopia© site (http://www.execpc.com/~gopalan/) or mail him at gopalan@gmx.net.
|
This site, developed and maintained by Gopalan Suresh Raj |
|
Last Updated : May 10, '02 |
||
Copyright (c) 1997-2002, Gopalan Suresh Raj - All rights reserved. Terms of use. |
All products and companies mentioned at this site are trademarks of their respective owners. |

![]()